
앞에서 얘기했듯이 SQLite 라는 로컬 전용 데이터베이스를 이용하여 책 대여 프로그램의 내부를 설계해 보자. 먼저 얘기했듯이 실제 설치를 해서 실습을 한다고 했는데 SQLite 를 사용하는 방법은 크게는 3가지 정도가 있다고 볼 수 있다. 첫 번째는 SQLite 실행 파일만 다운로드 해서 윈도우의 CMD 창이나 맥의 Terminal 에서 실행하는 방법이 있고(맥은 사실 이미 SQLite3 가 기본으로 설치되어 있긴 한다고 한다). 두 번째는 파이썬이나 자바, .NET 같은 프로그램을 이용해서 호출하는 건데 보통 이 경우는 기본 패키지에 포함되어 있거나, 추가로 패키지를 설치해 쓴다고 보면 될 듯 하고, 마지막 방법이 SQL 쿼리를 도와주는 "DB Browser for SQLite" 같은 DB 클라이언트 프로그램을 사용하는 거다.
사실 이런 SQLite 같은 작은 로컬 기반의 디비가 아닌 경우는 위의 3가지 중 어느 방법을 쓰더라도 보통 SQL 서버 자체를 별도로 구축해야 하는 경우를 빼 먹을 수는 없겠지만, SQLite 는 특별하게 비 설치 형으로 아주 작은 형태의 로컬 환경에서의 디비 제공을 지향하는 프로그램이기 때문에 위와 같이 간단한 방식이 가능하다고 보면 될 것 같다. 다른 종류의 데이터베이스와의 차이는 우선 여기서 SQLite 이해한 후 다음 얘기에서 한번 비교하여 풀어보자. .
사실 데이터베이스의 사용을 얘기하려면 위의 3가지 방법을 다 이해하는 게 맞긴 해서 어떻게 할지 고민 하다가, 우선은 앞의 SQLite 웹 사이트에서 실습 한 것과 비슷한 모습을 보여주는 "DB Browser for SQLite" 를 사용해 실습 해 보여주고, 뒤에 파이썬으로 프로그램을 만들어 조회를 해보거나, 마지막에 CMD 나 Terminal 창에서 실제 명령어를 날려 조회하는 방식으로 움직이는 부분을 살짝 보여주고 마무리 하려 한다. 사실 요즘 엄청 핫 하게 얘기 되고 있는 AI Agent 들도 결국은 저 CMD 나 나중에 Nosql 에서 얘기할 API 를 기반으로 복잡하게 얽혀 AI 모델을 중심으로 마치 하나의 프로그램 같이 생각 되도록 움직이는 것에 가깝다고 보기 때문에 명령어 방식도 꼭 한번 보여주고 넘어가 보려 한다. 앞에서 얘기했듯이 IT 세상에서는 이해가 안되고 신기하게만 보이면 안되기 때문이다.
참고로 이젠 실습이기 때문에 굳이 한 땀 한 땀 따질 필요가 적고, 아는 지식을 기반으로 AI 검색 엔진을 사용해서 기본 쿼리 들을 만들게 할 건데, 이 글의 진행에서는 무료로 사용 가능한 Gemini Flash 버전을 비 로그인 상태에서 사용하고 있으니 참고 부탁 드린다.
앞에서 윈도우, 맥 상에서 모두 시연이 가능하도록 한다고 약속을 했으니, 우선 DB Browser for SQLite를 2개의 OS에서 설치하는 방법부터 보자. 일단 어느 OS 이던 구글에서 "db browser for SQLite" 를 우선 검색해 보자. 가장 처음에 나오는 "https://sqlitebrowser.org" 사이트를 클릭 해서, "Download" 페이지로 가보자.
[윈도우 용 DB Browser for SQLite 설치 및 쿼리 실행 해보기]
먼저 윈도우의 경우는 실제 프로그램으로 설치, zip 파일을 해제해서 실행, 하나의 파일로 된 포터블 실행 파일 버전 3가지가 있다. 어느 걸 설치해도 무방하지만 혹시 직접 설치하는 게 좀 그렇다면, "DB Browser for SQLite - .zip (no installer) for 64-bit Windows" 를 다운로드 해서 아래와 같이 적절한 폴더에 압축을 풀어보자(개인적으로 c:\SQL 폴더를 만들어서 거기에 압축을 풀었다).

이후 DB Browser for SQLite.exe 파일을 실행하자. 아래와 같은 빈 프로그램 화면이 나오면 성공했다고 보면 된다.

처음이니까 쿼리를 만드는 데까지 자세히 설명하고, 이후부터는 원래 모드로 쿼리 위주로 다시 설명을 들어가려 한다. 우선 "새 데이터베이스" 버튼을 클릭해 보자. 컴퓨터에서 돌아가는 모든 프로그램들은 결국은 파일로 데이터를 저장하게 된다(물론 가끔 악성 코드 같은 경우는 메모리 상에서만 돌아가다가 없어지는 경우도 있지만, 메모리도 결국은 0과 1을 저장하는 휘발성 장소이기 때문에. 데이터의 구조를 저장한 다는 측면에서는 디스크에 저장되는 파일과 특별히 다르지는 않다고 본다. 파일이라는 개념 또한 가상의 0과 1의 배열을 이용하여 내용을 저장하기 위한 OS의 규칙이기 때문이다). 여하튼 현재 실행 폴더가 나오면 "mytest" 이름으로 저장해 보자.

이후 "테이블 정의 변경"이라는 창이 나오는데(데이터베이스를 만들었으니 테이블을 하나 만들어 보라는 뉘앙스다), 이건 그냥 우선 취소를 해서 닫자. UI 를 이용해서, 테이블 생성하기 같은 버튼을 눌러서 테이블을 만들 수도 있겠지만, 우린 이미 쿼리를 배웠으니 그냥 바로 쿼리로 얘기를 해보도록 하자.
위 쪽 메뉴에서 "SQL 실행" 탭을 누르면, 우리가 앞 글에서 봤던 웹 상의 편집기 같은 쿼리를 입력할 수 있는 메뉴가 나온다. 우리가 하나의 파일 형태의 데이터베이스를 만들었고, 이 SQLite 편집기의 특성 상 기본적으로 하나의 데이터베이스를 대상으로 작업하도록 되어있으니 앞으로의 모든 행동은 현재의 mytest 데이터베이스에 저장이 될 것이다(실제 프로그램이 실행된 폴더를 확인해 보면 "mytest.db" 라는 파일이 생성되어 있다. 이 파일을 나중에 다른 곳으로 옮기면 앞으로 작업하는 모든 데이터가 다 같이 옮겨가게 된다).
그럼 테스트 테이블을 하나 만들어 보자. AI 한테 부탁해서 일련번호가 들어가는 과자 테이블을 하나 만들었자.
CREATE TABLE snacks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL
);
전체에 대해서 명령을 날리려면, 입력한 내용을 아무 것도 선택하지 말고 F5키를 누르거나 위의 프린트 아이콘 오른쪽 옆에 있는 재생 모양의 화살표를 누르자. 이후 밑을 보면 아래와 같이 쿼리가 잘 실행 됐다는 결과 텍스트가 나온다.

여기서 왼쪽에 있는 "데이터베이스 구조" 탭을 클릭해 보면 아무것도 없던 테이블 영역에 2개의 테이블이 생긴 것을 볼 수 있다. 컬럼의 데이터 형이나 속성들을 비주얼 하게 펼쳐서 볼 수도 있다(혹시나 sqlite_sequence 테이블이 왜 생겼는지 궁금하다면 마찬가지로 궁금해 찾아봤는데, AUTOINCREMENT 속성 땜에 각 테이블 별로 자동 증가하는 id 값이 현재 몇 번인지 저장해 두는 용도로 SQLite 에서 쓰는 내부 테이블이라고 한다).

다시 쿼리 쪽으로 가서 이번엔 과자 이름들을 넣어보자, 앞에서 설명했듯이, id 는 자동 증가되기 때문에 대상 컬럼 이름에서 빠져있다.
INSERT INTO snacks (name) VALUES ('새우깡');
INSERT INTO snacks (name) VALUES ('초코송이');
INSERT INTO snacks (name) VALUES ('포카칩');
마찬가지로 이제 굳이 촌스럽게 "데이터베이스 구조" 탭으로 가지 않아도 앞에서 쿼리 설명할 때처럼 머리 속으로 논리적으로 상상을 해보자. 네모난 "snacks" 테이블을 하나 만들고, 데이터 3줄을 넣었구나 하고 말이다.

마지막 실습으로, 아래의 조회 쿼리를 마찬가지로 실행해 보면, 우리가 상상한 대로 데이터가 들어 있다는 것을 보여주게 된다. 매번 비어있던 가운데 공간이 예상 했던 대로 데이터 값이 조회 시 출력 되는 공간 이였었다.
SELECT * FROM snacks;

하나 주의할 점은 마치 엑셀 작업한 내용을 저장하지 않음 날라가듯, 프로그램 종료 전에 저장을 안 하면 모든 내용이 없어지게 된다. "파일 > 변경사항 저장하기", "파일 > 프로젝트 저장하기(이건 현재 입력한 쿼리라든지 창 배치 등을 저장해 준다고 한다)"로 저장해 주거나, 종료 할 때 저장을 묻는 경우 모두 저장을 해주자. 간단히는 엑셀처럼 메모리 상에서 작업하다가 파일로 저장된다고 생각해도 무방할 듯 싶고, 조금 데이터베이스 입장으로 얘기로 하자면 트랜젝션(Transaction-일련의 전체 셋으로 꼭 성공해야 되는 쿼리 작업 단위)의 개념으로 생각해서 "rollback" 가능한 상태로 메모리 상에 존재하다가, 작업이 완전히 끝나서 "commit" 됐다고 보면 될 것 같다. 약간 SQLite 는 완전 파일 기반으로 표현하므로, 아마 해당 DB Browser 프로그램이 워드나 엑셀 같은 데이터의 "저장" 이라는 용어로 쉽게 다가가도록 표현된 듯 싶긴 하다.
자 그럼 테스트를 완료하고, 다시 창을 띄우게 되면 다시 빈 공간만 보이게 되는데(최근 작업 파일을 가져오는 옵션이 있는지는 모르겠다), 커스터마이즈한 작업 공간을 복구하고 싶으면 "파일 > 프로젝트 열기"를 하여 "mytest.sqbpro" 파일을 읽어오고, 아까 저장한 데이터베이스를 가져와 다른 작업을 하고 싶다면 "파일 > 데이터베이스 열기"를 이용해서 아까 저장한 mytest.db를 가져와 보자. 해당 상태로 기존 만들었던 테이블과 데이터가 그대로 보이게 된다면, 앞으로의 실습 준비는 끝났다고 보면 될 듯 싶다.
[맥 용 DB Browser for SQLite 설치 및 쿼리 실행 해보기]
이번엔 맥북을 보자. 위의 윈도우 섹션은 당연히 안 보았으리라 생각하고 비슷하게 반복적으로 얘기를 적으니 양해 바란다. 마찬가지로 해당 페이지로 이동 해서, 다운로드 버튼을 눌러서 다운로드 후 프로그램을 더블 클릭해 어플리케이션으로 등록해 주자.

이후 DB Browser for SQLite.exe 파일을 실행하자. 아래와 같은 빈 프로그램 화면이 나오면 성공했다고 보면 된다.DB Browser for sqliteDB Browser for sqliteDB Browser for sqlite 실행

처음이니까 쿼리를 만드는 데까지 자세히 설명하고, 이후 부터는 원래 모드로 쿼리 위주로 다시 설명을 들어가려 한다. 우선 "New Database" 버튼을 클릭해 보자. 컴퓨터에서 돌아가는 모든 프로그램들은 결국은 파일로 데이터를 저장하게 된다(물론 가끔 악성 코드 같은 경우는 메모리 상에서만 돌아가다가 없어지는 경우도 있지만, 메모리도 결국은 0과 1을 저장하는 휘발성 장소이기 때문에 디스크에 저장되는 파일과 특별히 다르지는 않다고 본다. 파일이라는 개념 또한 가상의 0과 1의 배열을 이용하여 내용을 저장하기 위한 OS의 규칙이기 때문이다). 폴더는 "Documents"로 하고 "mytest" 이름으로 저장해 보자.

이후 "Edit table definition"이라는 창이 나오는데(데이터베이스를 만들었으니 테이블을 하나 만들어 보라는 뉘앙스다), 이건 그냥 우선 취소를 해서 닫자. UI 를 이용해서, 테이블 생성하기 같은 버튼을 눌러서 테이블을 만들 수도 있겠지만, 우린 이미 쿼리를 배웠으니 그냥 바로 쿼리로 얘기를 해보도록 하자.
위 쪽 메뉴에서 "Execute SQL" 탭을 누르면, 우리가 앞 글에서 봤던 웹 상의 편집기 같은 쿼리를 입력할 수 있는 메뉴가 나온다. 우리가 하나의 파일 형태의 데이터베이스를 만들었고, 이 SQLite 편집기의 특성 상 기본적으로 하나의 데이터베이스를 대상으로 작업하도록 되어있으니 앞으로의 모든 행동은 현재의 mytest 데이터베이스에 저장이 될 것이다(실제 저장한 Documents 폴더를 보면 "mytest.db" 라는 파일이 생성되어 있다. 이 파일을 나중에 다른 곳으로 옮기면 앞으로 작업하는 모든 데이터가 다 같이 옮겨가게 된다).
그럼 테스트 테이블을 하나 만들어 보자. AI 한테 부탁해서 일련번호가 들어가는 과자 테이블을 하나 만들었다.
CREATE TABLE snacks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL
);
전체에 대해서 명령을 날리려면, 입력한 내용을 아무 것도 선택하지 말고 F5키를 누르거나 위의 프린트 아이콘 오른쪽 옆에 있는 재생 모양의 화살표를 누르자. 이후 밑을 보면 아래와 같이 쿼리가 잘 실행됐다는 결과 텍스트가 나온다.

여기서 왼쪽에 있는 "Database Structure" 탭을 클릭해 보면 아무것도 없던 테이블 영역에 2개의 테이블이 생긴 것을 볼 수 있다. 컬럼의 데이터 형이나 속성들을 비주얼 하게 펼쳐서 볼 수도 있다(혹시나 sqlite_sequence 테이블이 왜 생겼는지 궁금하다면 마찬가지로 궁금해 찾아봤는데, AUTOINCREMENT 속성 땜에 각 테이블 별로 자동 증가하는 id 값이 현재 몇 번인지 저장해 두는 용도로 SQLite 에서 쓰는 내부 테이블이라고 한다).

다시 쿼리 쪽으로 가서 이번엔 과자 이름들을 넣어보자, 앞에서 설명했듯이, id 는 자동 증가 되기 때문에 대상 컬럼 이름에 빠져있다.
INSERT INTO snacks (name) VALUES ('새우깡');
INSERT INTO snacks (name) VALUES ('초코송이');
INSERT INTO snacks (name) VALUES ('포카칩');
마찬가지로 이제 굳이 촌스럽게 "Database Structure" 탭으로 가지 않아도 앞에서 쿼리 설명할 때처럼 머리 속으로 논리적으로 상상을 해보자. 네모난 "snacks" 테이블을 하나 만들고, 데이터 3줄을 넣었구나 하고 말이다.

마지막 실습으로, 아래의 조회 쿼리를 마찬가지로 실행해 보면, 우리가 상상한 대로 데이터가 들어 있다는 것을 보여주게 된다. 매번 비어있던 가운데 공간이 예상 했던 대로 데이터 값이 조회 시 출력 되는 공간 이였었다.
SELECT * FROM snacks;
하나 주의할 점은 마치 엑셀 작업한 내용을 저장하지 않음 날라가듯, 프로그램 종료 전에 저장을 안하면 모든 내용이 없어지게 된다. "File > Write Changes", "File > Save Project(이건 현재 입력한 쿼리라든지 창 배치등을 저장해 준다고 한다)"로 저장해 주거나, 종료할때 저장을 묻는 경우 모두 저장을 해주자. 간단히는 엑셀 처럼 메모리 상에서 작업하다가 파일로 저장된다고 생각해도 무방할 듯 싶고, 조금 데이터베이스 입장으로 얘기로 하자면 트랜젝션(Transaction-일련의 전체 셋으로 꼭 성공해야 되는 쿼리 작업 단위)의 개념으로 생각해서 "rollback" 가능한 상태로 메모리 상에 존재하다가, 작업이 완전히 끝나서 "commit" 됬다고 보면 될 것 같다. 약간 SQLite 는 완전 파일 기반을 표현하므로, 아마 해당 DB Browser 프로그램이 워드나 엑셀 같은 "저장" 이라는 용어로 쉽게 다가가도록 표현된 듯 싶긴하다.
자 그럼 테스트를 완료하고, 다시 창을 띄우게 되면 다시 빈 공간만 보이게 되는데(최근 작업 파일을 가져오는 옵션이 있는지는 모르겠다),, 커스터마이즈한 작업 공간을 복구하고 싶으면 "File > Open Project"를 하여 "mytest.sqbpro" 파일을 읽어오고, 아까 저장한 데이터베이스를 가져와 다른 작업을 하고 싶다면 "File > Open Database"를 이용해서 아까 저장한 mytest.db를 가져와 보자. 해당 상태로 기존 만들었던 테이블과 데이터가 그대로 보이게 된다면, 앞으로의 실습 준비는 끝났다고 보면 될 듯 싶다.
혹시나 나중에 MSSQL이나, Oracle, MySQL, PostgreSQL 등 여러가지 파일이 아닌 서버(서비스) 형태의 디비를 쓰더라도 마찬가지로 이런 비슷한 쿼리를 날릴 수 있는 SQL 클라이언트(SQL 서버에 쿼리를 날리는 고객이라서 SQL 클라이언트다)를 설치하거나, 클라우드라면 내부 또는 SAAS 서비스로 제공 되는 여러 툴 들을 이용해서 쿼리를 비슷하게 날리게 된다.
나중에 얘기할 NoSQL 도 좀 더 개발 쪽 친화적이여서 모양만 낯설 뿐 비슷하다고 보면 된다. 다만 서버 형태의 데이터베이스들의 경우는 원격의 서비스 이기 때문에, 앞의 데이터베이스 파일 열기 같은 형태가 아니라 마치 우리가 웹 사이트에 로그인 할 때처럼 보통 ID, Password 를 넣어서, SQL 서버에 로그인 후 해당 세션을 유지하며 쿼리를 날리게 되고, 이 것을 정보를 입력하면 해당 클라이언트가 그런 자잘한 일들은 자동으로 해주게 된다.
자 그럼 실습을 할 수 있는 환경은 준비가 됐으니 이젠 다시 쿼리의 세계로 여행을 떠나보자. 앞에서 얘기한 대로, 프로그램하고 연결은 안 되 있지만 데이터베이스와 쿼리를 이용해서 책 대여점 프로그램을 만들어 보자(뭐 책 대여점이라는 개념이 낯설다면, 돈을 주고 빌려주는 유료 도서관 시스템이라고 생각해 보자).
시작하기 전에 잠시 프로그램의 세계를 엿보자면 어느 순간부터 프론트엔드, 백엔드로 경계를 나눠서 얘기하고 있었는데, 지금은 다시 어느 쪽이든 API 를 기준으로 한 비동기 프로그램이 대세가 되고, 프론트엔드도 점점 엄격한 객체지향의 세계로 변하게 되면서, 구경하는 서당 개의 입장에서 보면 두 개의 프로그램 스타일의 경계가 다시 무너지는 느낌도 들긴 하지만, 뭐 굳이 따지자면 데이터베이스 관련된 테이블과 쿼리의 설계는 백엔드 쪽에 속한다고 볼 수는 있을 것이다. 사실 디비를 중심으로 한 쿼리 중심으로 보면 외부의 프로그램 코드는 해당 쿼리들을 적절히 설계 후에 비즈니스 규칙에 맞춰서 쿼리 들을 UI 의 요청에 맞춰 적절히 호출하는 일을 주로 담게 된다.
물론 ORM(Object-Relational Mapping) 같은 방식으로, 구조적으로 디비를 정의해 User.find(1) 이런 식으로 쿼리를 자동으로 만들어주어 개발자 쪽에서 쿼리를 인지 못하게 할 수도 있지만 내부적으로는 결국 마지막에는 데이터베이스에 쿼리를 날리는 SQL 이 실행된다는 부분에서는 SQL 을 이해해야 한다는 결론에는 크게 다르진 않는 듯도 싶다. 음 뭐 나중에는 해당 부분의 번역 또한 AI 실시간으로 실행 시 해주게 되면 상황이 변하게 될 것은 같긴 하지만, 어쨌든 모든 결과의 실행은 실제로 데이터베이스 입장인 SQL 세상에서 일어나게 된다.
요즘 핫한 OS 에서 돌아가는 AI Agent 들도 결국은 맨 마지막에서는 구닥다리 윈도우 API 나 CLI, 타 솔루션의 API 등을 호출해서 정교한 명령을 수행하게 될 테니까 말이다. 뭐 언젠가 AI 가 더 발전해서 세상의 모든 기술이 굳이 인간이 이해할 필요가 없는(아마 무생물인 AI 관점에서는 가독성에 치중된 꽤 비효율적인 인터페이스 일 수도 있을테니 말이다) 바이너리 같은 코드와 기술로 다 컨버전되어 바뀌어 버리기 전에는 이건 당분간 바뀌진 않을 것 같다(아마 현실 측면에서는 구현된 기술의 저작권 문제도 있을 거다). 아마도 그래서 이러한 미래의 레거시 후보가 될 뒷 세계의 모양을 아는 것이 현재 정확하게 AI 가 미치는 세상을 이해하는데 도움이 될 것 같긴 하다. 앞에서 얘기했지만 현재 얘기하는 SQL 도 그런 측면에서 이해하는데 의미가 있다. 다시 한번 의견을 말하자면 IT 쪽에서 기술이 이해하기 힘든 마법같이 보임 절대 안 된다고 생각한다. 뭐 약간의 발전을 위한 긍정적인 환타지는 허용되야 할테지만 말이다.
그럼 다시 현실로 돌아와서 책 대여점 프로그램에 어떤 게 필요할지 생각을 해보자. 자 우선 그전에 우리가 사용하고 있는 RDB(Relational Database) 가 뭔지 생각해 보자. 보통 복잡하게 얘기하긴 하는데 야매 입장에서 보면 RDB 가 처음 나왔던 시절은 디스크 등의 용량이 엄청 비쌌던 시절이다. 몇 십 메가의 하드가 주력이던 시절이니 말이다(WD Caviar 93044 같은 모델이 40MB 라고 한다). 그래서 그 당시 중복된 데이터를 저장한다는 것은 아마 엄청 사치스러운 접근법이였을테고, 기본적으로 중복되지 않은 데이터를 저장하는 것을 보통 정규화라는 조금 어려운 학술 표현으로 쓰는 것 같다.
그래서 지금의 많은 RDB 테이블에서 볼 수 있는 상품 정보, 주문 정보 등의 테이블로 분리되면서 실제 길이가 긴 상품 명은 상품 테이블에만 저장되고 주문 정보 테이블에서는 상품 번호만 저장하는 식으로 중복 데이터를 최소화 하는 식으로 저장되었고, 주문 정보에서 상품 정보를 같이 보여주기 위해서 필연적으로 우리가 골치 아파하는 JOIN 키워드와 빠른 JOIN을 도와주는 인덱스라는 존재가 꼭 필요하게 됐다고 볼 수 있다(현재의 NoSQL이나 현대적인 RDB 설계의 측면에서는 이 부분을 역으로 접근했다고 생각해 보자).
이 방식은 하나의 얘기치 않은 장점도 있는데, 중요한 키워드 데이터들이 수많은 테이블 중에 보통 한 군데에만 들어가므로(예를 들면 상품 가격은 상품 테이블에만 있거나 또는 상품 코드를 가진 가격 테이블에만 있을 수 있다), 중복된 데이터 중 특정 컬럼 데이터의 업데이트를 놓쳐서 생기는 무결성의 깨짐 부분을 방지하는 효과를 가져온다. 또한 일반적으로 단일 서버 기준으로 데이터를 저장하므로 아무래도 무결성을 유지하면서도 빠르다.
NoSQL 은 JOIN 같은 장점과 무결성을 조금은 포기하면서 서버를 병렬적으로 늘려 지금의 AI가 나온 빅데이터를 가능케 한 접근 방식이라고 보면 될 것 같고, 요즘은 두 개를 합쳐 다수의 서버로 속도와 무결성을 유지하려 하는 NEWSQL 이라는 서버군 들도 생겨나고 있다고 한다(설명을 보면 약간 NoSQL와 정해진 서버 들까지의 투표로 진위를 가리는 기업 용 블록체인 장부가 합쳐진 느낌이라고 할까 싶다). 여하튼 뭐 이런 확장된 부분들은 관심이 있다면 직접 해당 서버들을 사용하거나 구축하면서 장 단점을 느껴보면 되지 않을까 싶다.
자 그럼 중복된 데이터를 저장 안 하려 하는 RDB 의 특징을 생각하면서 책 대여 프로그램의 뒷 편 설계를 해보자.

먼저 책을 저장하는 테이블이 하나 있음 좋겠다. 다른 테이블과 조인할 때 쓸 수 있는 고유 일련 번호는 당연히 있어야 하고, 책 이름도 있어야 한다. 대여 가격도 포함해 볼까 했지만 그럼 같은 금액이 엄청 많이 있을 텐데, 나중에 책마다 금액을 바꾸고 싶어 할 경우 책이 많아진다면 뭔가 엄청 많은 데이터를 업데이트 해야 될 수도 있어 보여서 일종의 책 종류 코드를 대신 넣고 가격 테이블은 책 종류 코드에 따라 부여되게 별도로 저장해 보려 한다. 그럼 RDB 의 기본 목표처럼 저장되는 데이터 크기도 아끼고, JOIN 쪽도 그다지 부담은 안 될 것 같다.
책 코드에 따라서 대여기간 등도 조정 가능하도록 테이블로 관리할 수 있을 것 같다(이걸 프로그램 로직에서 관리할지 데이터베이스에 넣을지 고민을 할 수도 있겠지만, 프로그램을 새로 만드는 것보다는 데이터베이스의 값을 간단히 업데이트 하는 게 편할 듯 해 보인다. DBA 쪽에서 변경 시 작업해야 되는 번거로움은 생길지 모르겠지만 보통 이런 중요한 값이라면 관리되는 admin 페이지가 있어서 감사 로그와 함께 저장될 가능성이 높다).
회원 가입 시 받아야 할 정보도 있을텐데, 현재 시점에서 꼭 필요한 개인정보만 생각하면 이름, 고유정보를 체크하거나 연체 독촉 시 사용할 핸드폰 전화번호만 생각하면 될 것 같다. 직접 입력하는 회원 아이디도 굳이 이쪽에서 찾을 때 필요한 부분이니 필요가 없을 듯하다, 나머지 추가적인 정보 들은 차후 고민해 보자.
책을 빌려주게 되는 상황이 되면 대여에 관한 테이블이 하나 필요할 것 같다. 대여 번호가 고유키 일거고, 조회 시 중요한 필드는 회원 아이디가 될 것 같고, 들어가는 값들을 책의 일련번호, 현재 날짜가 들어가는 대여 시작일, 대여 종료 일은 책 종류에 따라 대여 일수를 정하려 하니(만화책 3일, 소설 5일 등) 아까의 책 가격 테이블을 확장 시켜서, 책 코드 별로 가격에 대여 기간도 같이 저장해 보자. 나중에 대여 기간을 연장 한다던지 하는 여러 기능이 추가될 수도 있고, 특정 시기에 대여 기간 정책을 바꿀 수 있기 때문에 시작 일과 종료 일은 명확히 하는 게 좋겠다. 또 해당 대역의 상태를 관리하기 위해서 하나의 상태 코드를 만들면 좋을 거 같다. 처음 대여 했을 때는 Rent 로 했다가 반납하게 되면 Return 상태가 되도록 하게 말이다. 음 연체료를 계산하거나 실제 반납 일이 다른 수 있으니 반납 일도 하나 넣는 것도 좋겠다.
이렇게 생각하다보니 거래나 너무 많아지게 되면 나중에 테이블에서 이런 부분을 조회하는 부분이 부담이 될 것도 같지만 현재 프로그램의 특성 상 그렇게 많은 데이터가 쌓이진 않을 듯 하니, 반납이 완료된 히스토리 테이블을 따로 분리하는 건 차후에 고민하도록 해보자.
위와 같은 고민으로 AI 한테 부탁할 테이블 정보를 정리해 봤다. 아무래도 모두 우리말로 적다보면 테이블이나 컬럼 이름 같은 걸 너무 딱딱하게 적어서 맘에 안 드는 경우가 있어서, 지금 까지 배운 쿼리 지식을 이용해서 하나하나 최대한 정의를 해봤다. AI 가 알아서 잘 해주는 거 같은 Foreign 키 정의 같은 건 일단 그냥 빼놓자.
| 책 대여하는 프로그램을 sqlite 로 설계를 해보려고 해. 아래와 같은 테이블 들을 간단히 만들고 싶어. 1) 일단 책을 저장하는 테이블은 book 으로 하고, 책 일련번호(book_no), 책 제목(book_name), 책 타입(book_type - 나중에 가격이나 대여기간을 여기다 넣으려해) 컬럼을 만들어줘. 책이 대여나 파손, 또는 불가 상태가 되면 대여 가능 상태 여부를 알 수 있게 status 컬럼도 하나 만들어 줄래? 여기서 아마 고유 값은 book_no 만 있을 거 같네. 2) 책 종류에 대한 대여 정책 정보를 관리하는 book_policies 테이블을 만들고, 여기는 책 타입(book_type) 과 가격(price), 대여 기간(rental_period) 컬럼을 만들어줘. 아 연체시 하루 연체료(penalty_per_day) 도 넣어야 할 거 같네. 나중에 혹시 코드별 가격이나 대여기간 변경이 필요하면 이 테이블을 수정하려 해. 여기서는 book_type이 고유 값이 될거 같아. 3) 회원정보(customers) 테이블은 최소한의 개인정보만 저장하려해서 회원 고유 아이디(customer_id), 회원 이름(name), 한국 핸드폰 번호기준(phone), 회원 가입일(reg_date)만 넣으려해. 이름은 중복이 가능하니 핸드폰 번호(또는 이름+핸드폰 번호)가 아마 손님이 왔을때 검색하는 고유키가 될거 같네. 나머지는 기능이 확장되면 고려해 보려고. 여기서는 customer_id 와 phone이 중복이 있음 안 될거 같아. 4) 책 대여 테이블(book_rentals) 을 만들려 하는데, 대여 일련번호(rental_no), 회원 아이디(customer_id)가 주요 where 조건 키 일 거 같고(하지만 여러권을 책을 빌릴 수 있으니 회원 아이디는 중복은 있을 거야), 책 일련번호(book_no)와 나중에 혹시 대여기간 등이 변경 될수도 있으니 빌려줄 당시의 대여 시작일(rental_start_date)과 대여 종료일(rental_end_date)을 넣고 싶어. 또 대여, 반납, 취소 등의 상태를 관리하는 상태 코드(status)와 반납일(return_date)도 있음 좋겠어. 거래가 완료된 건만 타 테이블로 분리해 이관하는건 나중에 데이터가 많아짐 고민해 보려고. 여기서는 rental_no 이 중복 값이 없을 거 같아. 5) 조금 과한거 같긴 하지만 매출 등의 계산을 위해서 book_borrow_history 테이블을 만들려해 하다가 그냥 대여 테이블(book_rentals)에서 조회 할까도 싶은데 어떻게 생각해? |
자 그럼 위의 내용을 기반으로 AI 가 만들어 준 테이블 정보를 보면서 우리가 의도한 대로 만들어 줬나 생각해 보자(이걸 직접 해봤던 사람들은 이런 게 얼마나 귀찮고 인형 눈 끼우는 거 같은 일인지 잘 알고 있을 것이다.
1) 결과적으로 히스토리 테이블은 나중에 규모가 커지면 만들라고 하고, 아래와 같이 4개의 테이블을 만들어 주고, 앞에서 얘기한 데이터가 많을 경우 검색을 빠르게 하기 위한 인덱스도 추천해 줬다.
2) 책 정책 테이블은 책 타입을 고유 값("PRIMARY KEY") 으로 해서 중복을 막으면서 인덱스를 만들고, 가격이나 기간은 연체료는 꼭 입력 시 있도록 강제 하기 위해서 "NOT NULL" 코드가 들어갔다. SQLite 는 데이터 형태가 간단해서 글자는 TEXT, 숫자는 INTEGER 로 정의했다.
CREATE TABLE book_policies (
book_type TEXT PRIMARY KEY, -- 책 타입 (고유 값)
price INTEGER NOT NULL, -- 대여 가격
rental_period INTEGER NOT NULL, -- 대여 기간 (일 수)
penalty_per_day INTEGER NOT NULL -- 연체료 (하루당)
);
3) 책 정보 테이블은 책 일련 번호를 고유 값으로 하고, 자동("AUTOINCREMENT") 증가 되게 했다. book_type 은 외래키("FOREIGN KEY")로 해서 book_policies 에 들어 있지 않는 값이 못 들어 가도록 방지 했다. status 는 적당히 대화를 해석해서 네 개의 상태 값(가능, 대여 중, 훼손, 분실)이 들어가는 걸로 가정했는데, 뭐 그냥 실습이니 나쁘지 않아 보이니 넘어가자. 또한 status 는 빈 값이 들어올 경우 "AVAILABLE" 이 들어간다.
CREATE TABLE book (
book_no INTEGER PRIMARY KEY AUTOINCREMENT, -- 책 일련번호
book_name TEXT NOT NULL, -- 책 제목
book_type TEXT, -- 책 타입 (외래키 후보)
status TEXT DEFAULT 'AVAILABLE', -- 상태 (AVAILABLE, RENTED, DAMAGED, LOST)
FOREIGN KEY (book_type) REFERENCES book_policies(book_type)
);
여기서 하나 좀 애매한 부분이 있는데, status 와 book_type 이 "NOT NULL" 조건이 없다는 부분이다. 아마도 AI 생각을 추측해 보면 status 는 default 가 있어서 값을 안 넣어도 'AVAILABLE' 을 자동으로 넣어주어 괜찮고, book_type 은 외래키가 이상한 값을 막아 줄거라고 생각해서 뺀 거 같은데, 현실 적으로 보면 아래와 같은 쿼리에 대해서 실제 NULL 이 들어가는 이슈가 있을 수 있다(궁금하면 위의 테이블의 이름을 book_test 로 만들어서 직접 넣어보자).
INSERT INTO book (book_name, status) VALUES ('SQL 테스트', NULL);

그래서 명시적으로 2개의 필드도 not null 이 들어가는 게 맞을 것 같고, 해당 부분을 다시 AI 한테 물어보니 그게 맞을 것 같다고 의견을 조정했다. 그럼 아래와 같이 조정할 수 있다. 대신 이 경우는 하나의 단점이 status 를 꼭 지정해 넣어줘야 한다는 부분이다. null 어떻게든 안 넣거나 막을 자신이 있으면 "NOT NULL"을 빼는 것도 하나의 선택지일 것도 같다.
CREATE TABLE book (
book_no INTEGER PRIMARY KEY AUTOINCREMENT, -- 책 일련번호
book_name TEXT NOT NULL, -- 책 제목
book_type TEXT NOT NULL, -- 책 타입 (외래키 후보)
status TEXT NOT NULL DEFAULT 'AVAILABLE', -- 상태 (AVAILABLE, RENTED, DAMAGED, LOST)
FOREIGN KEY (book_type) REFERENCES book_policies(book_type)
);
4) 회원 정보 테이블도 날짜에 NOT NULL 이 없어서 추가했고, 나중 코드를 보면 알겠지만 SQLite 는 날짜 형이 실제 없다고 하고, 쿼리 상에서는 날짜 같이 취급되지만 실제로는 TEXT 로 저장된다고 한다. 가벼운 효율성을 위해서 그랬다나 한다. 여기도 중복 안 되야 하는 값을 고유 값을 하고, 핸드폰의 경우는 고유 값은 아니지만(이걸 고유 값으로 잡으면 개인정보를 모든 다른 테이블의 키로 잡아야 해서 당연히 적절치 않아 보인다) 겹치는 값이 들어가면 안 되는 실제의 내부 고유 값 이여야 하므로, 겹치는 값이 못 들어가는 제한을 주기 위해 "UNIQUE" 를 넣었다.
CREATE TABLE customers (
customer_id INTEGER PRIMARY KEY AUTOINCREMENT, -- 회원 고유 아이디
name TEXT NOT NULL, -- 이름
phone TEXT UNIQUE NOT NULL, -- 핸드폰 번호 (중복 불가)
reg_date DATE NOT NULL DEFAULT (DATE('now')) -- 회원 가입일
);
5) 대여 테이블도 마찬가지로 status 에 "NOT NULL"을 추가했고, return_date 야 말로 빌려주자마자 반납 하는 경우는 당연히 없을 테니, 나중에 필요한 순간에 날짜가 들어가게 NULL 허용이 되게("NOT NULL" 이 없음 허용이다) 했다. 마찬가지로 똑똑하게 customer_id, book_no 는 회원 테이블과 책 정보 테이블에 없는 값은 안 들어가도록 외래키를 걸어줬다.
CREATE TABLE book_rentals (
rental_no INTEGER PRIMARY KEY AUTOINCREMENT, -- 대여 일련번호
customer_id INTEGER NOT NULL, -- 회원 아이디
book_no INTEGER NOT NULL, -- 책 일련번호
rental_start_date DATE NOT NULL, -- 대여 시작일
rental_end_date DATE NOT NULL, -- 대여 예정일
return_date DATE, -- 실제 반납일
status TEXT NOT NULL DEFAULT 'RENTED', -- 상태 (RENTED, RETURNED, CANCELLED)
FOREIGN KEY (customer_id) REFERENCES customers(customer_id),
FOREIGN KEY (book_no) REFERENCES book(book_no)
);
6) 이 밖에 status 값도 AVAILABLE, RENTED, DAMAGED, LOST 네 개로 제한(CHECK (status IN ('AVAILABLE', 'RENTED', ...)) 하자는 의견도 있었는데, 이건 안정성 보다는 상태가 새로 생길 때마다. 제약 조건을 업데이트 해야 하는 부분이 걸려서 그대로 두기로 한다.
7) 회원이 방문했을 때 찾는 키가 이름하고 폰 번호일 것 같아서 아래와 같이 이름하고 전화번호 컬럼에 인덱스를 거는 것도 제안 했는데, 이것도 결국은 실제에서는 전화번호 뒷자리 4자리로 찾는 게 개인정보 보호 상 현실적일 것 같아서, 나중에 전화번호 뒷자리 컬럼을 하나 더 만드는 게 날 것 같긴 해서 실습에서는 넘어간다.
CREATE INDEX idx_customer_search ON customers(name, phone);
여하튼 AI 쪽에서는 범용적인 관점에서 내가 빼놓은 걸을 잘 체크해 주는 편이므로, 해당 부분을 잘 이용해서 비어 있는 부분을 잘 채우고 자신과 AI 둘 다 괜찮다고 생각하는 협의 점을 찾아보는 게 어떨까 싶다.
테이블 생성 후 데이터베이스 구조를 보면 아래와 같다. 중간에 null 테스트를 안 해봤다면 book_test 테이블은 없을 거다

그 다음에 테이블이 잘 만들어 진 것을 증명하고, 차후 프로그램에서 이런 저런 쿼리를 날렸을 때 잘 되려는 지 검증을 위해서 책을 등록 하고, 고객을 등록하고, 대여하고, 반납하는 간단한 시나리오에 대한 쿼리를 만들어 보자. 위의 테이블 들을 설계하면서 머리 속에 대충 테이블들이 이제는 그려졌을 테니, 그걸 기반으로 아래와 시나리오를 만들어 봤다.
| 시나리오를 한번 설명해 줄께. 관련된 쿼리를 만들어 줄래? not null 인 영역에 default 값이 있다고 빼먹고 그러진 말아줘. 그리고 상태 값이나 타입 값은 소문자로 부탁해 1) 책을 만화책(comic)과 소설(novel) 로 나눔. 각각 대여료는 500원, 1000원, 대여기간은 3일, 5일, 연체료는 하루에 100원, 200원 이야. 2) 책이 2권 들어왔는데 원피스(만화)랑, 채식주의자(소설)이야. 이 책들을 대여가 가능하게 등록 해야되. 3) 회원의 두 명 가입했는데 "홍길동"이 "010-1111-1111" 로 가입 했고, "김고객"이 "010-2222-2222" 로 가입 했어. 4) 이후 "홍길동"이 찾아와서 "이름, 전화번호 뒷자리로" 회원을 확인하고 원피스를 빌려갔어 5) 근데 10일 후에 책을 반납 했네. 7주일치 연체료를 계산해야 되. 6) 연체료를 받은 후에는 책을 반납해서 완료하려고. |
AI가 만들어 준 각각의 코드를 봐보자.
1) 책을 만화책(comic)과 소설(novel) 로 나눔. 각각 대여료는 500원, 1000원, 대여기간은 3일, 5일, 연체료는 하루에 100원, 200원 이야.
얘기한 대로 book_policies 테이블에 대여료, 기간, 연체료 기준으로 입력해 준다.
INSERT INTO book_policies (book_type, price, rental_period, penalty_per_day)
VALUES
('comic', 500, 3, 100),
('novel', 1000, 5, 200);
넣은 데이터를 조회해 보자
select * from book_policies

2) 책이 2권 들어왔는데 원피스(만화)랑, 채식주의자(소설)이야. 이 책들을 대여가 가능하게 등록 해야 되.
관련 책을 넣으면서 상태를 기본 상태인 'available' 로 만들어 준다.
INSERT INTO book (book_name, book_type, status)
VALUES
('원피스', 'comic', 'available'),
('채식주의자', 'novel', 'available');
넣은 데이터를 조회해 보자.
select * from book
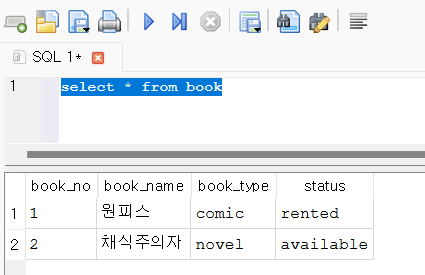
3) 회원 정보를 넣는다. 가입 일은 현재 날짜로 넣는다.
INSERT INTO customers (name, phone, reg_date)
VALUES
('홍길동', '010-1111-1111', DATE('now')),
('김고객', '010-2222-2222', DATE('now'));
넣은 데이터를 조회해 보자.
select * from customers

4-1) 사실 원래의 프로그램이라면 WHERE 조건에 좀더 간단해 질 수도 있고(이미 로그인 할때 customer_id를 가져와서 그걸 계속 사용한다거나), select 를 통해서 정보를 조회헤 온후, 해당 정보를 기반으로 insert 할 수도 있을 것 같다. 여기서는 하나의 쿼리로 나타내기 위해서 아래와 같이 insert 와 select 가 결합된 형태로 나타났다. "vaulus" 키워드가 사라진게 좀 특이해 보인다. 날짜는 SQLite 에서 지원하는 방식으로 현재(DATE('now'))와 현재에 대여기간을 더 한 형태(DATE('now', '+' || p.rental_period || ' days'))로 보여준다. 참고로 이런 날짜를 계산하는 방식은 데이터베이스마다 보통 조금씩 다르다.
INSERT INTO book_rentals (customer_id, book_no, rental_start_date, rental_end_date, status)
SELECT
c.customer_id,
b.book_no,
DATE('now'),
DATE('now', '+' || p.rental_period || ' days'),
'rented'
FROM customers c
JOIN book b ON b.book_name = '원피스'
JOIN book_policies p ON b.book_type = p.book_type
WHERE c.name = '홍길동' AND c.phone LIKE '%1111'
LIMIT 1;
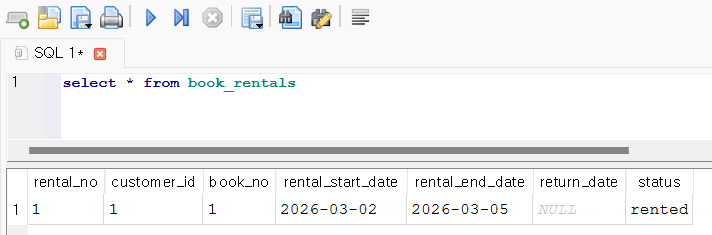
넣은 데이터를 조회해 보자.
select * from book_rentals
4-2) 추가로 도서 상태도 대여로 바꾸어줘 보자.
UPDATE book
SET status = 'rented'
WHERE book_name = '원피스';
업데이트 된 데이터를 조회해 보자.
select * from book WHERE book_name = '원피스';

5) 연체료 계산을 하다보니 테스트로 만든 쿼리라고 강제로 빌린 기간에 10일을 더 해서(DATE(r.rental_start_date, '+10 days')), 반납일로 정해 봤다. 그러다 보니 조금 헷갈리긴 할 듯 하다. 지난 기간을 체크하기 위해서 날짜를 JULIANDAY 라는 함수로 변환 후 다시 CAST 하는데, JULIANDAY 는 "기원전 특정일" 로 부터 흐른 날이라고 하고, CAST AS INTEGER는 원래 해당 값이 실수로 나올 수 있는데, 그걸 소수점을 버리는 거다. 여러 현실 적인 부분에서 연체로 계산하는 날짜 계산 방식이 바뀔 수 있는데(뭐 예를 들면 밤 11시에 빌리나 오전 11시에 빌리나 다음날 반납해야 되는 불공평함을 어떻게 개선해 본 다든지), 그 경우는 현재 날짜만 저장하는 DATE 를 DATETIME 으로 바꾸거나 하는 일이 생길 수도 있다. 여하튼 모든 건 목적을 위해서 설계하기 나름이라고 보자.
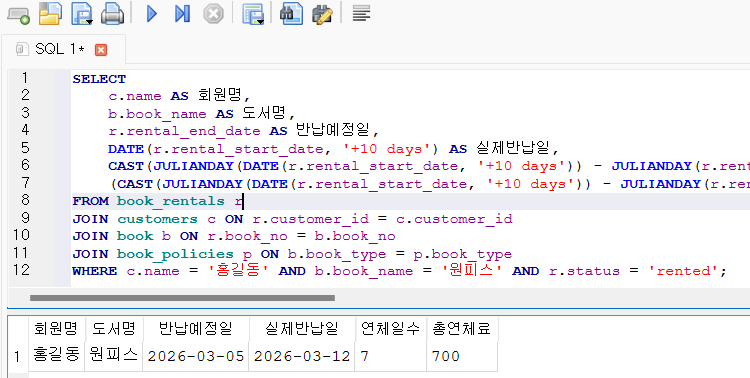
밑의 쿼리는 WHERE 조건에서는 약간 단정적으로 "홍길동"이라는 사람이 "원피스"를 빌려갔다고 가정하는데, 사실 현실에서는 이름은 고유 값이 아니기 때문에 특정 customer_id 의 현재 미 반납 목록 이라든지 그런 걸 볼 수 있으므로, WHERE 조건은 얼마든지 바뀔 수는 있어 보인다. 오히려 c.name은 고유 값이 아니므로 저렇게 사용하기가 좀 위험해 보이긴 하는데, 스크립트와 결과에 맞춰 쿼리를 만들어 주다 보니 그렇지 않을까 싶긴 한다.
SELECT
c.name AS 회원명,
b.book_name AS 도서명,
r.rental_end_date AS 반납예정일,
DATE(r.rental_start_date, '+10 days') AS 실제반납일,
CAST(JULIANDAY(DATE(r.rental_start_date, '+10 days')) - JULIANDAY(r.rental_end_date) AS INTEGER) AS 연체일수,
(CAST(JULIANDAY(DATE(r.rental_start_date, '+10 days')) - JULIANDAY(r.rental_end_date) AS INTEGER) * p.penalty_per_day) AS 총연체료
FROM book_rentals r
JOIN customers c ON r.customer_id = c.customer_id
JOIN book b ON r.book_no = b.book_no
JOIN book_policies p ON b.book_type = p.book_type
WHERE c.name = '홍길동' AND b.book_name = '원피스' AND r.status = 'rented';
6-1) 마지막으로 대여한 사람이 10일 후에 반납했다고 보자. 밑의 조건은 관점에 따라 약간 과할 수도 있는데, 특정 사용자 id 와 책을 상태를 굳이 맞추는 것 보다, 스캐너로 스캔한 책 번호와 status 만 있어도 될 것 같 긴 한데, 그래도 확실히 하려면 빌려간 id 도 보는 게 날테니 일단 그대로 두자.
UPDATE book_rentals
SET return_date = DATE(rental_start_date, '+10 days'),
status = 'returned'
WHERE customer_id = (SELECT customer_id FROM customers WHERE name = '홍길동' AND phone LIKE '%1111')
AND book_no = (SELECT book_no FROM book WHERE book_name = '원피스')
AND status = 'rented';
6-2) 책도 정상 상태로 돌려주자.
UPDATE book
SET status = 'available'
WHERE book_name = '원피스';
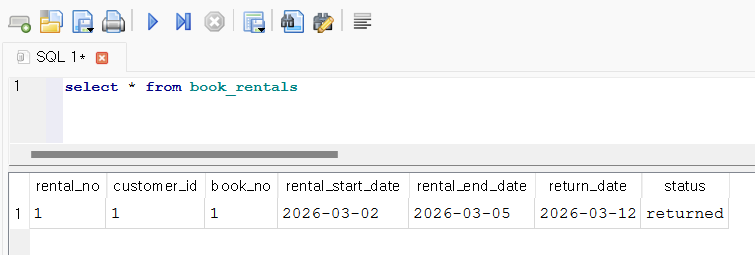
마찬가지로 앞에서 수행했던 쿼리들을 이용해서 book_rentals 와 book 테이블이 업데이트 된 부분을 보자.

다음엔 여기까지 온 김에 프로그램에서 쿼리를 호출하는 모습도 한 번 봐보자.
밑의 코드는 AI 쪽에서 추천해 준 대로 streamlit 이라는 파이썬 라이브러리를 가지고 윈도우에 만들어 놓은 SQLite 파일을 기준으로 만들어준 코드이다.
import streamlit as st
import sqlite3
import pandas as pd
from datetime import datetime
# 1. 데이터베이스 연결 함수
def get_data():
conn = sqlite3.connect('c:\Sql\DB.Browser.for.SQLite-v3.13.1-win64\mytest.db')
# 오늘 날짜를 기준으로 대여된 현황 조회 쿼리
query = """
SELECT
r.rental_no AS '번호',
c.name AS '회원명',
b.book_name AS '도서명',
b.book_type AS '타입',
p.price AS '대여료',
r.rental_end_date AS '반납예정일',
r.status AS '상태'
FROM book_rentals r
JOIN customers c ON r.customer_id = c.customer_id
JOIN book b ON r.book_no = b.book_no
JOIN book_policies p ON b.book_type = p.book_type
WHERE r.rental_start_date = DATE('now')
"""
df = pd.read_sql(query, conn)
conn.close()
return df
# 2. 스트림릿 UI 구성
st.set_page_config(page_title="오늘의 대여 현황", layout="wide")
st.title("📚 오늘 도서 대여 관리 현황")
st.write(f"조회 일시: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
# 데이터 불러오기
df = get_data()
if not df.empty:
# 요약 정보 (메트릭)
col1, col2 = st.columns(2)
col1.metric("오늘 총 대여 건수", f"{len(df)}건")
col2.metric("오늘 총 매출", f"{df['대여료'].sum():,}원")
st.divider()
# 데이터 표 출력
st.subheader("📋 상세 대여 리스트")
st.dataframe(df, use_container_width=True, hide_index=True)
else:
st.info("오늘 대여된 내역이 없습니다.")
# 새로고침 버튼
if st.button('데이터 새로고침'):
st.rerun()
여기 서는 과정은 설명 하진 않고, 간단한 실행 모습과 결과만 보겠다. 해당 내용을 파이썬 파일(rental_book.py)로 저장 후, CMD 창에서 실행한 결과 이다. 파이썬을 조금 안다면 파이썬을 설치하고, 라이브러리를 설치하고, 파일을 실행하면 바로 된다. 일단 한 가지 주의할 점은 앞에서 얘기했지만 SQLite 는 로컬 디비 이기 때문에 지금까지 한 작업을 저장을 해야 이후 외부에서 해당 데이터에 실제 접근이 가능하다. DB Browser for SQLite 에서 "파일 > 변경사항 저장하기"를 꼭 실행 해주자.
c:\Python\Code\linkedin>streamlit run rental_book.py
실행 하면 아래와 같이 깔끔한 페이지가 나오게 되는 데, 이건 파이썬 프로그램이 코드 중간에 있는 Sqlite 파일의 위치(결국 데이터베이스 위치)와 query 변수 안에 넣은 쿼리를 가지고 Sqlite 에 조회를 해서 결과를 얻은 후 해당 결과를 라이브리리에 잘 전달을 해서 결과를 보여준다(여기에 사실 테이블 형태의 데이터 정리를 도와주는 pandas 라는 라이브러리도 있는데 뭐 지금은 코드를 배우는 시간은 아니니 그려러니 하자).
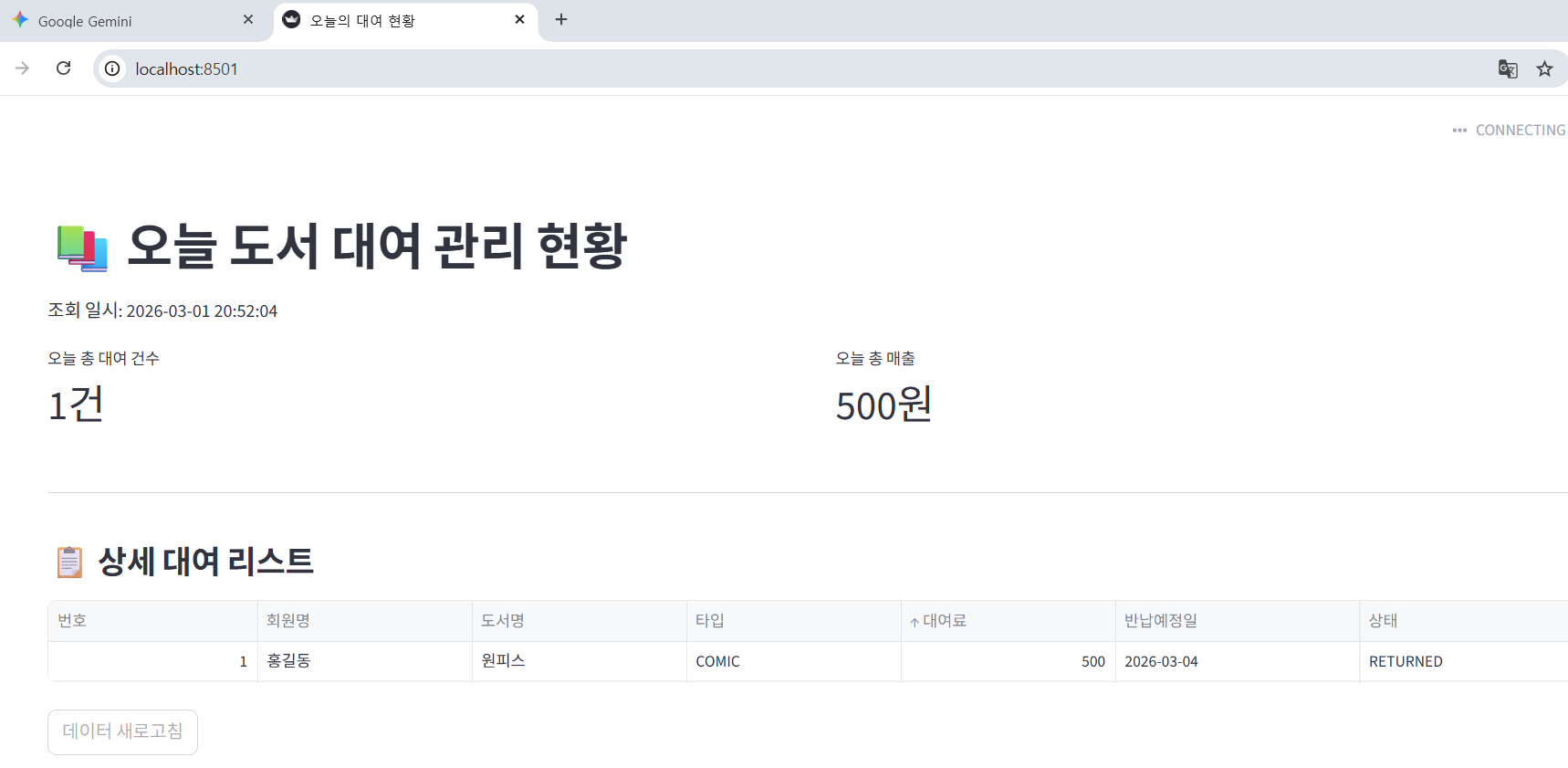
실제 저 코드 안의 query 라는 변수 안에 있는 SQL 쿼리 문장(이제는 우리는 잘 구분할 수 있다)을 긁어다 DB Browser에서 조회하면 아래와 같이 동일한 데이터를 볼 수가 있다. 다만 프로그램에서는 저 모양 그대로가 아닌 여러 프로그램 로직으로 가공한 그래프를 포함한 다양한 모습으로 데이터들의 표현이 가능할 것이다.
마지막으로 CMD 에서 실행하는 예제만 보고 마무리를 해보자. 이것도 실습을 할 건 아니라서 해보고 싶은 사람을 위해서 간단히 설명하자면, https://www.sqlite.org/download.html 사이트에서 sqlite-tools-win-x64-3510200.zip를 다운로드해 압축을 풀고 압축을 푼 디렉토리로 가서 CMD 창에서 아래와 같이 실행하고, "sqlite>" 로 입력 프롬프트가 바뀌면 이후 밑의 쿼리를 넣어본다.
c:\Sql\sqlite-tools-win-x64-3510200>sqlite3 c:\Sql\DB.Browser.for.SQLite-v3.13.1-win64\mytest.db
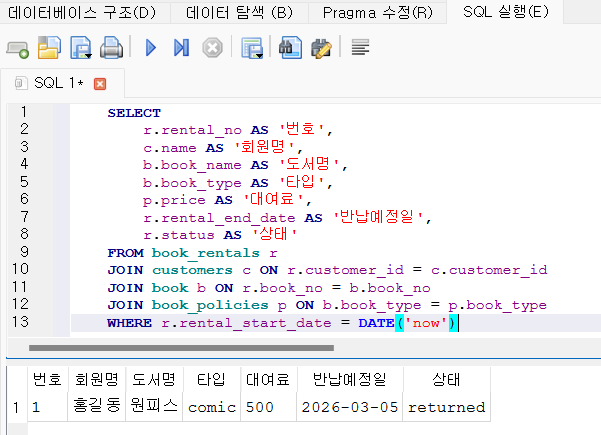
SELECT
r.rental_no AS '번호',
c.name AS '회원명',
b.book_name AS '도서명',
b.book_type AS '타입',
p.price AS '대여료',
r.rental_end_date AS '반납예정일',
r.status AS '상태'
FROM book_rentals r
JOIN customers c ON r.customer_id = c.customer_id
JOIN book b ON r.book_no = b.book_no
JOIN book_policies p ON b.book_type = p.book_type
WHERE r.rental_start_date = DATE('now');
이건 실행된 그림으로 대신 한다.

왠지 글이 길어질 거 같아서 손을 못 대고 있었는데 역시 꽤 길어지긴 했고(이 정도 글이면 링크드인 편집기가 좀 많이 버벅댄다;), 다행히 억지로 마무리는 된 듯하다. 생각보다 조회 쿼리가 많지 않아서 좀 따라가기가 힘들 것 같긴 한데 그대로 전체적인 사이클을 한번 보여주는 게 좋을 것 같아서 CRUD 를 골고루 섞어 봤다(지금 보니 D 는 중간에서 테스트 하다 개인적으로 지우기만 했긴 했다). 사람들이 데이터베이스에 이렇게 쿼리를 날리기는 하지만 실제에서는 그보다 몇 백만 배로 프로그램들(여러가지 API 나 어플리케이션)에서의 호출이 일어나는 게 더 많다고 보면 된다. 어찌 보면 뒤에서 여러 종류의 데이터베이스를 또 살펴 보겠지만 IT의 심장 같은 느낌을 가지게 된다.
RDB에서 보통 프로그램에서는 성능 상의 이유로 저 WHERE 뒤의 변수 들을 고정 시켜 놓고, 해당 값들을 프로그램 내에서 가공해서 넣게 된다. 예를 들면 로그인 할 때 아이디, 해싱된 패스워드를 기준으로 유효한 cusommer_id를 메모리에 잘 저장한 후, 해당 값을 인자로 하는 여러 종류의 Query 를 호출하면서 데이터베이스로부터 가져와 프로그램에서 이용하게 된다. 조금 억지로 확장하자면 데이터베이스를 사용하지 않는 프로그램들도 그 나름대로의 데이터를 저장하는 구조를 가지고 해당 데이터를 처리하고 교환하면서 움직이게 된다. 그래서 데이터베이스를 이해하는 것이 어찌 보면 프로그램을 쉽게 이해하는 길이고, 또 프로그램 세상을 이해하는 것이 요즘 한참 얘기 되는 AI 가 만드는 자동화된 agent 의 세상이나 자동화된 프로그램을 쉽게 이해하는 한 발판이 되어주지 않을까 생각한다. 개인적으로는 데이터베이스가 데이터의 심장을 목표로 한다면 AI 는 로직의 심장을 목표로 하는 거 같다고 보기 때문이다. 아직 손발을 이루는 기술은 그대로가 아닌가도 싶다.
여하튼 여기에서 쿼리 자체를 설명하는 부분을 마치고, 다음 번에는 다른 여러 서버 형식의 RDB 가 현재의 SQlite 와 어떤 다른 포지션을 가지고 있는지 보려고 한다. 그 후에는 NoSQL을 함 보려하고, 그 담에 아직은 조금 애매한 기타 디비들, 그 담엔 보안에서의 데이터베이스를 얘기 잠깐하고 마무리를 향해 달려갈까 생각은 하고 있다.
<Fin>
'프로그래밍' 카테고리의 다른 글
| SQL 이해해보기 #04 - 정교하게 타겟하기 (1) | 2026.03.02 |
|---|---|
| SQL 이해해보기 #03 - 관계에 대해 살펴보기 (0) | 2026.03.02 |
| SQL 이해해보기 #02 - 쿼리가 만들어지는 과정 (1) | 2025.12.21 |
| SQL 이해해보기 #01 - 데이터베이스와 테이블 이해하기 (0) | 2025.12.21 |
| SQL 이해해보기 - 들어가면서 (0) | 2025.12.21 |











